

The standardised AI usage event
Every source — a LiteLLM webhook, a Langfuse trace, a Bedrock log, a Databricks usage row — is normalised to one canonical shape before anything else happens. It rides on Flexprice’s standard event (event_name, external_customer_id, properties, timestamp, source), with a fixed convention for AI properties.
Following Flexprice’s event format, all
properties values are sent as strings; Flexprice interprets numeric fields during aggregation.Connector types
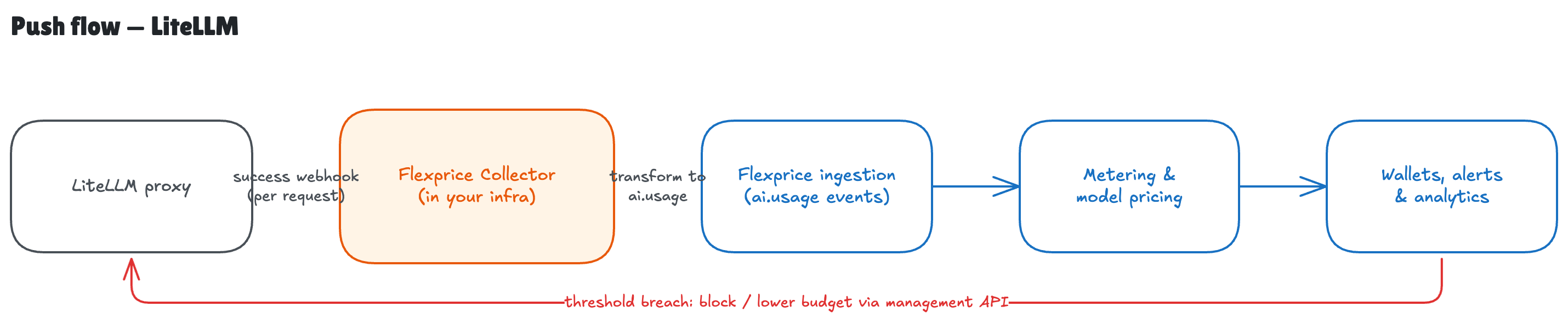
Sources differ in whether they can push in real time, must be polled, or only expose aggregate totals. Flexprice covers all three with the same downstream pipeline.Push flow (e.g. LiteLLM)
Managed pull flow (e.g. Langfuse, Databricks, Bedrock)
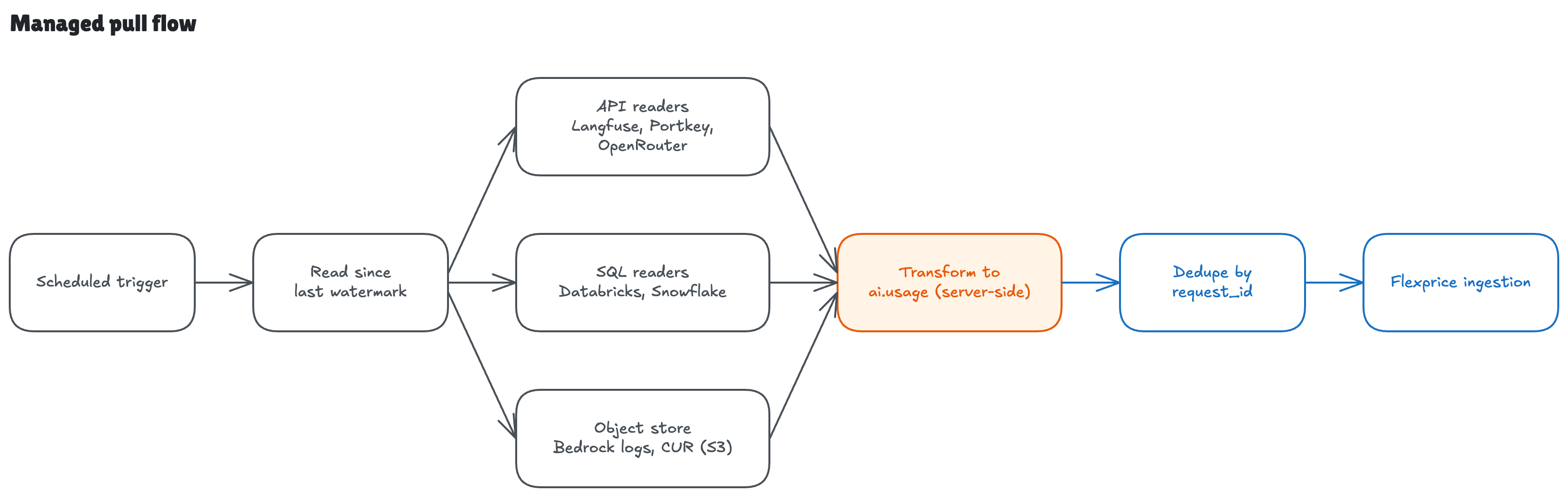
request_id dedupe guarantees no double counting across overlapping pulls.
Integrating LiteLLM
LiteLLM is a real-time push source: it fires a logging callback on every completion, already carrying token counts, USD cost, model, and identity. There are three ways to wire it into Flexprice — from drop-in to fully custom — and all three emit the same standardisedai.usage event. You never define meters, features, or prices for this; enabling the LiteLLM connector with a template provisions them.
Option 1 — Flexprice SDK callback (recommended)
Register the Flexprice callback and you’re done — no payload mapping, no transform to maintain. Everycompletion() call you already make is metered.
ai.usage, and ships it — one event per request, attributed to the team (with the user kept as a child for per-user and per-agent visibility).
Option 2 — LiteLLM Proxy (no code)
If you run the LiteLLM Proxy, enable the Flexprice callback inconfig.yaml. Every request routed through the proxy — from any app, agent, or MCP server — is metered and attributed to the virtual key’s team/user, with nothing to deploy in your services.
Option 3 — Custom callback (full control)
When you want to shape the event yourself — add tags, override the entity, or filter calls — implement a LiteLLMCustomLogger and send the event with the Flexprice SDK. This is exactly what Option 1 does under the hood, exposed for you to customise.
The event Flexprice receives
Whichever option you pick, the same canonical event lands — already mapped, ready to be priced and attributed:Closing the loop — enforcement
Because Flexprice now holds the source of truth for spend, a budget breach can act back on LiteLLM (the dashed return path in the push-flow diagram). On awarning/critical alert, Flexprice calls LiteLLM’s management API with your master key to throttle the offending key or team:
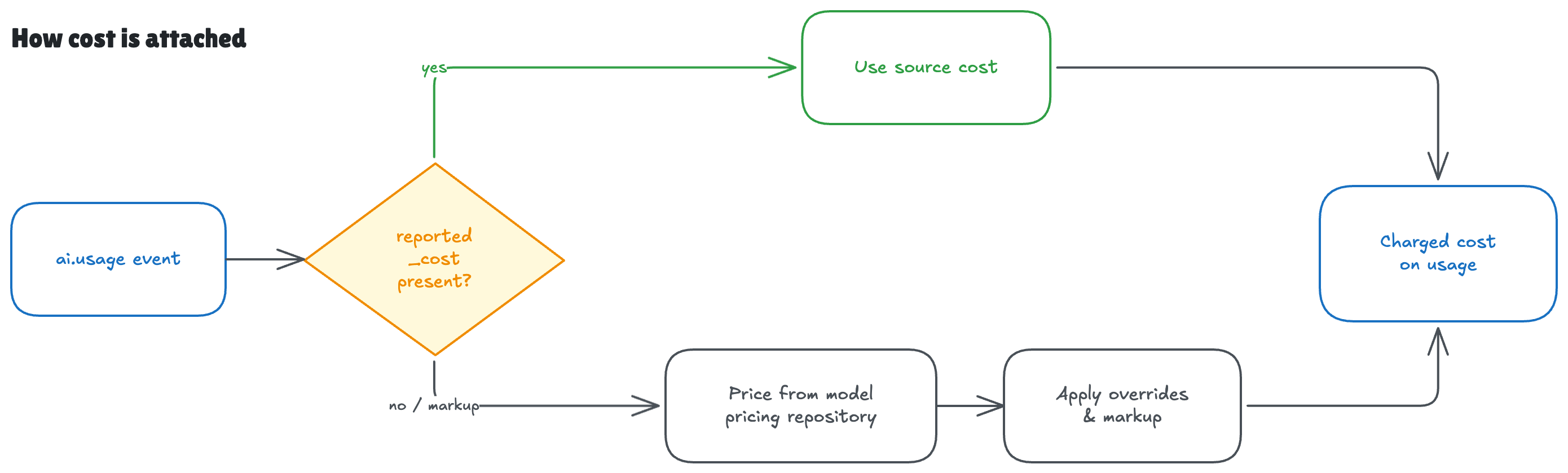
How cost is attached
Most modern gateways compute USD cost themselves, so Flexprice uses that by default and re-prices only when it needs to.- Trust the source cost (default) — when
reported_costis present (LiteLLM, OpenRouter, Portkey, Langfuse, Helicone, Cloudflare, Vercel), Flexprice stores it as-is. This correctly captures negotiated and BYOK rates. - Re-price from the catalog — when a source provides tokens only (Bedrock logs, Databricks token usage) or you want markup/margin or a single normalised price across gateways, Flexprice prices from its model pricing repository.
Auto-provisioning metering
Enabling a connector and choosing a template creates the metering graph for you — no manual meters, features, or prices.cost_tracking— meters for input/output/cached/reasoning tokens and request count, features per dimension, and catalog pricing at cost. For internal showback.team_budget— the above plus a wallet, a recurring monthly credit grant, andinfo/warning/criticalalerts wired to gateway enforcement. For team and agent budgets.resale_markup— catalog re-pricing with a configurable margin, plus margin analytics. For AI features you bill customers for.
group_by on the provider and model properties, so there is no meter-per-model explosion — a handful of generic meters cover every model.
Identity and hierarchy resolution
Each connector maps source identifiers to a Flexprice billing entity and, optionally, builds the hierarchy:- A primary field (for example
raw_team) resolves to the customer being metered. - Additional fields (
raw_user,agent_id) create child entities under it, using Customer Hierarchy for individual visibility with consolidated rollups and shared wallets. - Unrecognised identifiers can auto-create entities or map to an existing
external_id.
Source coverage
Phase one deliberately spans every connector type so the model is proven against the hard cases:Coverage expands continuously — Helicone, OpenRouter, Portkey, Snowflake Cortex, TrueFoundry, Cloudflare, Vercel, and SAP Joule follow the same connector model. Each new source is a connector definition plus pricing entries, not a change to your setup.
Related
AI Cost Tracking overview
The problem, the solution, and the high-level architecture.
Flexprice Collector
The Bento-based collector used for push and in-infra sources.
Event Ingestion
The underlying event pipeline AI usage rides on.
Alerts and Notifications
Spend thresholds, states, and webhook delivery.